By Kent R. Kroeger (April 20, 2023)
Amazon’s “The Rings of Power” has not captured a large audience: What can they do now?
By Kent R. Kroeger (Source: NuQum.com, September 21, 2022)
[Disclaimer: The opinions (and errors) expressed in this essay are mine alone and do not represent the opinions of any of the media companies or creative properties mentioned herein.]
Amazon’s The Lord of the Rings: The Rings of Power TV series is going to be the most expensive TV show in history, with Amazon spending $465 million for its first season. When its five seasons are over, its total budget will be measured in the billions of dollars.
By comparison, HBO’s The House of the Dragon cost $200 million for its first season, and Netflix’s extraordinarily popular Stranger Things cost $270 million for its fourth season.
The problem for Amazon is that The House of the Dragon and Stranger Things are arguably audience-grabbing successes and, so far, it is not clear if The Rings of Power has found a mass audience.
When Season 4 of Stranger Things debuted in late June 2022, an estimated 301.3 million hours were watched, according to Netflix. As for The House of the Dragon, HBO reported 25 million people watched the August 2022 premiere in just over a week. Not to be outdone, Amazon reported the first episode of The Rings of Power, which debuted September 1, 2022, was watched by more than 25 million globally.
Would Netflix, HBO or Amazon shade the truth about their audience numbers? Of course they would. It would be criminally incompetent not to do so.
But how can we objectively decide if Stranger Things or The House of Dragons or The Rings of Power are, genuinely, popular with audiences? And how do they compare with each other?
Are streaming audience measurements believable?
At a time when consistent, credible audience measurement for streaming programs is still contentious, it is hard to find universally-accepted measures of audience interest in popular TV shows. They all have flaws.
Unfortunately, too many of the audience measurement stories published in the mainstream media use the content providers (e.g., Netflix, HBO, Disney+, etc.) as the primary sources for their own audience data. That isn’t journalism — that is called being a shill. More importantly, that is a recipe for unacceptable levels of corporate-friendly news bias.
Sadly, there are few audience data alternatives, particularly for independent researchers like myself who cannot justify the subscription fees for audience measurement services like Nielsen Media Research, Symphony Technology Group and GfK.
So I turn to Google Trends (GT). But is it an objective measure of audience interest? Probably not in the academic sense. The limited amount of quantitative analyses on GT’s objectivity and reliability suggests there are systematic biases in its data, and its ability to predict to predict consumer behavior (such as car sales) is dubious.
However, my own research has shown a strong correlation between GT search data and independent measures of TV streaming audiences.
It is entirely possible that GT statistics are biased and, nonetheless, a useful way to compare the relative popularity of streamed TV shows.
Of course, large corporations use their enormous financial resources to influence Google searches and other indicators of audience interest. They have every financial incentive to do so.
But it can also be assumed that the concerted actions of large corporations to manipulate social media and search engine numbers is a constant within the system. HBO (Warner Bros.) and Amazon are not resource-challenged, which is why data manipulation is unavoidable in today’s online media environment.
Yet, based on the evidence I’ve collected, GT remains a valuable, publicly-available data source for assessing the public’s interest in different media properties.
And if GT is a reliable data source, the news for The Rings of Power looks very grim, at least as of September 20, 2022.
‘The Rings of Power’ has not found an audience
Looking at Google search interest in the U.S. for The Rings of Power (TRP) and The House of the Dragon (THD) since their streaming debuts, THD is almost five times more interesting to Americans (see Figure 1).
Figure 1: Google search trends for The Rings of Power and The House of the Dragon (August 15 — September 20, 2022)
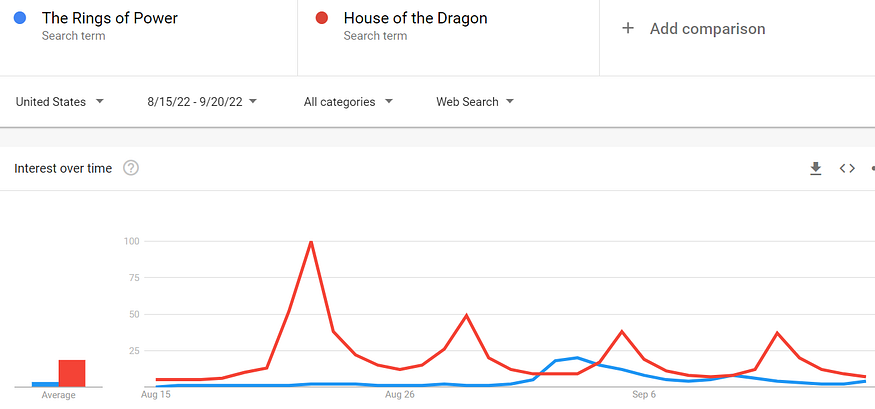
Amazon didn’t spend $465 million on TRP to generate levels of interest significantly below their arch rival, HBO. But compare Google search trends for TRP and THD to an undeniable TV series powerhouse, Stranger Things, and one must wonder if HBO and Amazon are themselves perennial runner-ups to Netflix (see Figure 2).
Figure 2: Google search trends for Stranger Things, The Rings of Power and The House of the Dragon (August 15 — September 20, 2022)
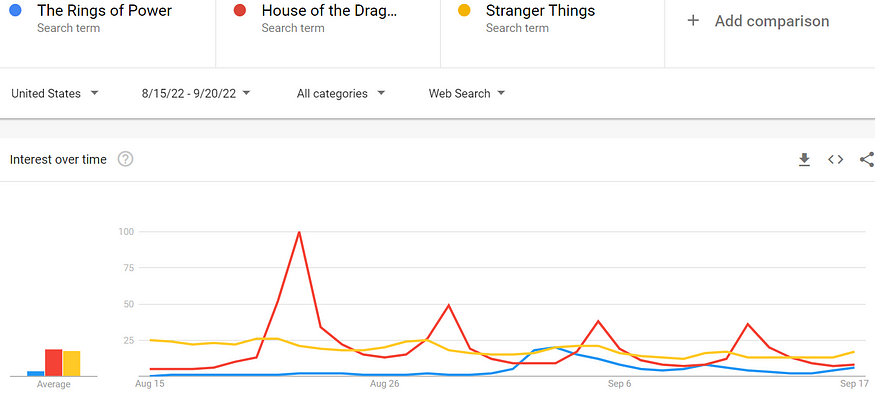
Stranger Things is two months removed from its 2022 season premiere and it still generates as much Google search interest (in the U.S.) as THD.
That is what a social phenomenon looks like.
TRP is not that.
When looking at the last seven days of Google searches, it is especially depressing for Amazon (see Figure 3). What should be Amazon’s harvest-time for TRP — the time when its episodes are new relative to its competitors — is turning out to be its deathblow.
Figure 23: Google search trends for Stranger Things, The Rings of Power and The House of the Dragon (September 14 — 21, 2022)
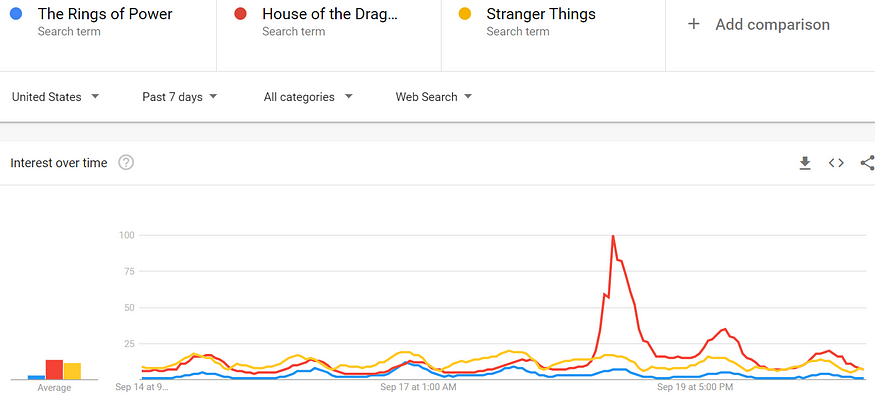
TRP hasn’t caught on with audiences. That is indisputable.
But can TRP recover?
‘The Rings of Power’ is good television
I don’t do movie or TV reviews in this blog. It’s not my strength nor my interest.
However, I find it baffling why TRP is not as popular, if not more popular, than THD.
My wife and son, both J.R.R. Tolkien readers, are totally engrossed in the TRP story line. Galadriel, played by Morfydd Clark, wonderfully represents TRP’s protagonist. She isn’t just beautiful, she dominates every scene she occupies. [Although, I wish the TRP writers knew how to give her a sense of humor.]
Galadriel is very watchable.
But critics point out that Galadriel is little more than a Karen — a white woman perceived as entitled or demanding beyond the scope of what is normal or earned.
Even woke-friendly media outlets are questioning the quality of TRP:
“The creators of Amazon’s The Lord Of The Rings: The Rings Of Power know how to create spectacle, but they don’t know how to tell a good story,” writes Forbes’ Erik Kain.
Other than losing her brother, there is no character arc in the TRP narrative that suggests Galadriel has suffered (or lost) in any significant way to authenticate her intense anger and power in her quest to defeat the illusive Sauron.
Identity politics, right or wrong, has infected the critical debate as to whether TRP is a great TV show.
And without missing a beat in that depressingly shallow political debate, Amazon has launched a social media campaign suggesting critics of TRP are themselves ‘racists’ and ‘misogynists.’
In responding to online criticism of Amazon’s conscious decision to make TRP more racially diverse than director Peter Jackson’s Lord of the Rings movies, TRP’s creators offered this rejoinder:
“We, the cast of Rings of Power, stand together in absolute solidarity and against the relentless racism, threats, harassment, and abuse some of our castmates of color are being subject to on a daily basis.”
In my opinion, when you find yourself responding to ‘online critics,’ you have already lost the debate. Moreover, calling your core audience ‘racist’ is a losing marketing strategy.
Write a good TV show and people will show up.
Write a less-than-good TV show, and you are reduced to name-calling.
That seems to be where Amazon and the creators of TRP reside today.
It is unfortunate, because the Tolkien fans in my household (which does not include me) are enjoying TRP. My teenage son loves Galadriel. That is something to build on, yes?
What can Amazon do to undue the damage TRP’s creators have inflicted on a TV series that should have been one of the defining moments in streaming TV history?
For what it is worth, I believe TRP’s writers need to make Galadriel vulnerable. She is too strong and powerful without the proper backstory to explain it.
We need to see Galadriel suffer on a heartbreaking level.
Until that happens, I don’t think anybody is going to care what happens in the next TRP episode.
- K.R.K.
Send comments to: kroeger98@yahoo.com

As censorship and secrecy rise, so do conspiracy theories
By Kent R. Kroeger (Source: NuQum.com, September 15, 2022)
Disclaimer: The following essay is not intended to endorse or promote any of the conspiracy theories mentioned herein.
The Joe Rogan Experience (JRE) was the most watched podcast on Spotify in 2021, reports Variety, and appears to be the most watched podcast across platforms in 2022.
Arguably, JRE reaches 11 million viewers per episode.
By comparison, the most popular cable TV news show, Tucker Carlson Tonight, garners between 2 and 4 million viewers per episode.
So when Rogan talks, millions of people listen. Perhaps only the U.S. president can get more attention on demand.
And while I remain a loyal JRE viewer, occasionally I cringe when Rogan speaks conspiracy theory nonsense. I forgave him years ago for once believing the moon landings were staged, but from all appearances he remains open to a belief that the 9/11 attacks were more than just an al Qaeda operation.
In particular, two years ago he helped sustain (while cagily showing skepticism towards) one of the most pernicious conspiracy theories still circulating in the cybersphere: that the 9/11 attacks on the World Trade Center towers were motivated by an attempt to coverup Pentagon financial malfeasance.
“The day before the 9/11 attacks, Rumsfeld gave a press conference where he talked about trillions of dollars missing. The next day a plane slams into the very part of the building where they were doing the accounting,” Rogan told his audience.
So what was Rogan implying? It’s rather obvious.
There is this indisputable fact: The day prior to the 9/11 attacks, Secretary of Defense Donald Rumsfeld gave a press conference announcing the results of a September 21, 2001 U.S. Department of Defense Office of Inspector General report (DoD-IG) which reported $2.3 trillion could not be adequately accounted for in DoD budgets.
Sometimes coincidences are just that…coincidences. That is one of reality’s laws that statistics repeatedly confirms.
Conspiracy theories are built on coincidences that reinforce pre-existing biases and narratives. If you believe the Pentagon and U.S. Intelligence Community (IC) in 1963 were so determined to pursue the war in Vietnam that its leaders were willing to see the assassination of a sitting president opposed to expanding that war, John F. Kennedy’s death makes more sense.
According to the documented evidence, a clearly dangerous man, Lee Harvey Oswald, took advantage of a poorly-prepared Secret Service in order to commit one of the greatest crimes of the century. Did he have help or was programmed to commit this crime? Those are questions that will never be answered sufficiently for many of us. [Jack Ruby’s role in this drama has never made sense to me.]
The truth is that we humans are biologically predisposed to reject randomness. We need explanations. “Life can feel especially senseless to someone whose belief in a purposeful, benevolent universe has been shattered by mercilessly unfair adversity,” says Ralph Lewis M.D., an assistant professor in the Department of Psychiatry at the University of Toronto.
A number of factors allow conspiracy theories to flourish. Firstly, the predilection of presidential administrations and the federal bureaucracy to believe that secrecy is more important to national security (and their legitimacy) than openness has consequences. The greater the government’s emphasis on secrecy, the more fertile the ground for popular conspiracy theories. [That is an hypothesis, not a conspiracy theory.]
Secondly, with increased secrecy, grows distrust. According to public opinion data, the public’s distrust in the nation’s institutions remains near historic lows. And as distrust of the government grows within the general public, the more likely conspiracy theories prosper. [Again, that is an hypothesis, not a conspiracy theory.]
Lastly, the growing determination of our nation’s elected officials to impose censorship on large segments of the general population (and a partisan segment of the general population willing to condone it), increases the opportunity for conspiracy theories to take hold within the public. [I’ll say it again, this an hypothesis, not a conspiracy theory.]
On an admittedly superficial level, the empirical evidence supports these hypotheses.
Figures 1 through 4 show the trends in literary references to the terms conspiracy theory, anonymous source, secret, and government censorship.
Our culture is growing increasingly exposed to these terms in our literature.
Figure 1: Trend in Literary Incidence of Term (1950 to 2019):
conspiracy theory
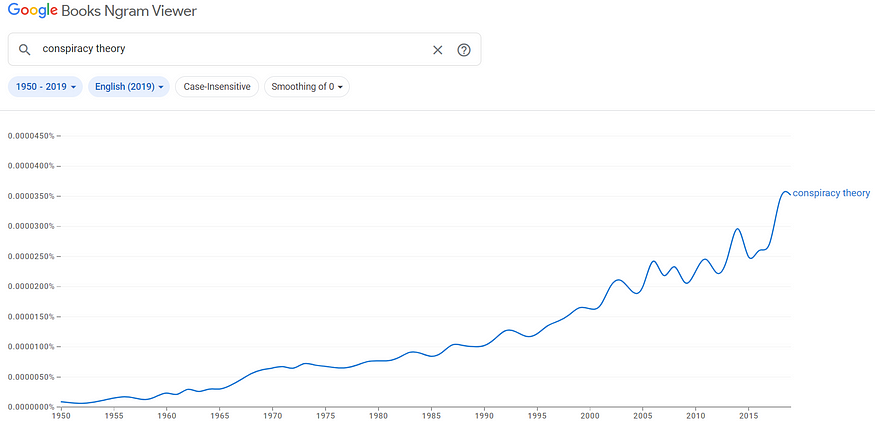
Figure 2: Trend in Literary Incidence of Term (1950 to 2019):
anonymous source
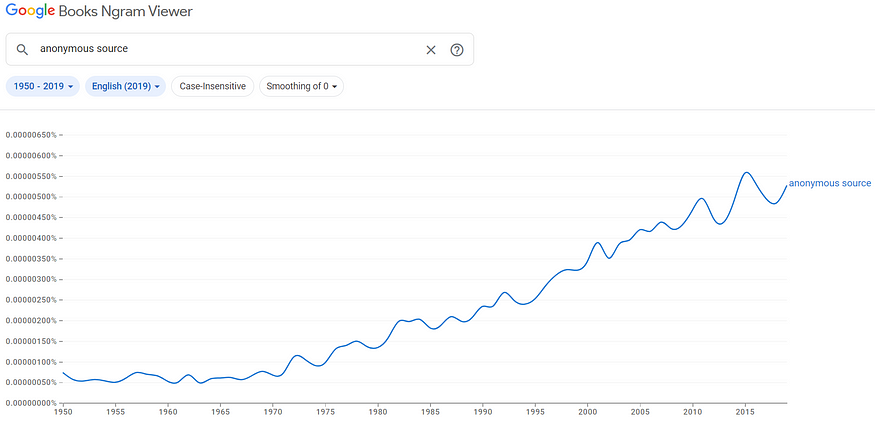
Figure 3: Trend in Literary Incidence of Term (1950 to 2019): secret
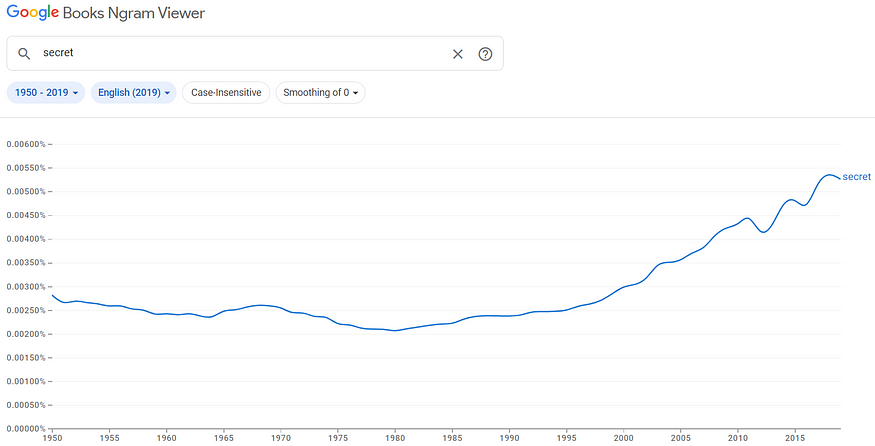
Figure 4: Trend in Literary Incidence of Term (1950 to 2019):
government censorship
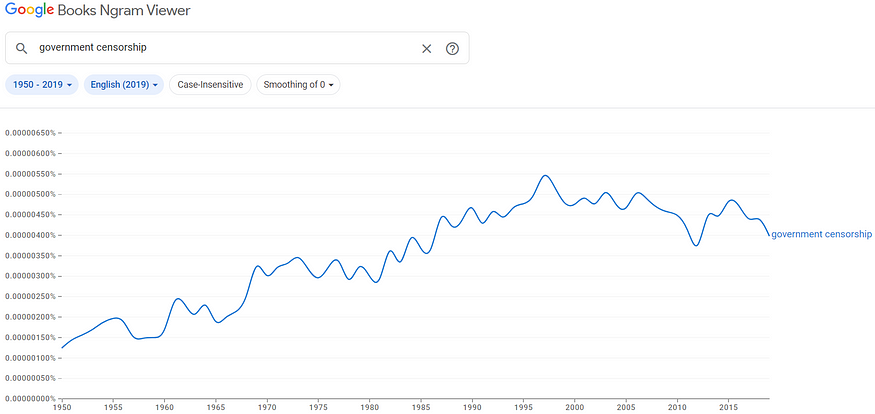
That is our culture today, increasingly exposed to (and subsequently numb to) stories of secrecy, censorship, and conspiracy theories.
And, based on evidence from GDELT, the largest and most comprehensive open database of human communications ever created, recent trends in global online news reinforces this conclusion (see Figure 5).
Figure 5: Trend in U.S. Online News Coverage (Jan. 2017 to Sep. 2022)
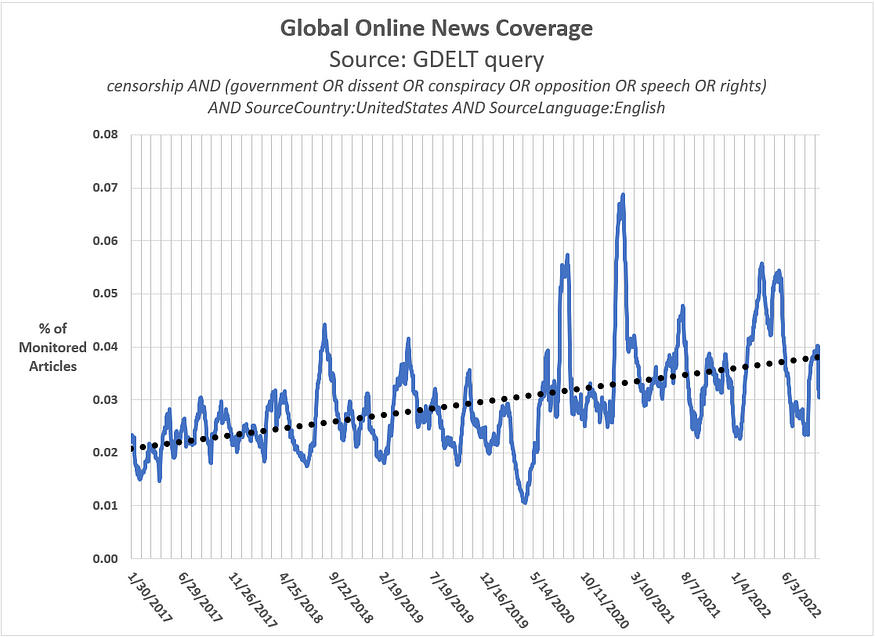
News stories about government censorship is on the rise in the U.S.
Does it reflect a genuine increase in government censorship? The anecdotal evidence says, ‘Yes,’ but the mere perception that it is increasing has its own repercussions.
Marginalized voices are feeling — right or wrong — more restricted than ever (i.e., leftist progressives, populist conservatives, etc.).
And conspiracy theories may be the main beneficiaries of their social diminishment.
Are conspiracy theories dangerous?
I have no fear of being exposed to conspiracy theories, the more absurd the better. As such, I am a regular consumer of such theories on imageboards like 4chan and 8chan (for entertainment purposes only, of course).
I cannot think of one case of something I’ve read on these imageboards that turned out to be substantively true. That is in contrast to a website like Wikileaks where I cannot think of one case where information on that site has been proven to be illegitimate.
Wikileaks is a legitimate source of news — 4chan and other dark-side imageboards are not.
So what is the problem with conspiracy theories? They are simply a symptom, not a cause of social unrest.
Truth be told, the prominence of conspiracy theories in the public discourse may be a ‘canary-in-the-mine’ indicator of how broken our political culture has become in recent years.
So what if I’ve read posts on 8chan suggesting the U.S. defense establishment created (or captured) the SARS-Cov-2 virus and dropped it in the middle of a Wuhan, China seafood market in order to stunt the Chinese economic growth miracle? [If true, they succeeded!]
Overwhelming, the evidence says such a theory is false. But why does the suggestion even exist?
This particular conspiracy theory exists because of the secrecy of the Chinese government (which we can’t control) and a U.S. public health establishment (which we can control) that thinks their role is paternalistic over the U.S. public (as opposed to an agent of the people’s constitutional power).
The best (and worst) conspiracy theories take a documented outcome (e.g., the deaths caused by the SARS-CoV-2 virus) and create theories as to why some segment of society might want and create such an outcome.
That is the greatest power of conspiracy theories. Using contrived theories to explain recognizable facts.
Critical Race Theory (CRT). White supremacy. The emerging Democratic majority. Islamic extremism. Transactivism. The Great Replacement Theory.
These are all sloppy social theories.
They aren’t science. They are politics…in its ugliest and most destructive form.
- K.R.K.
Send comments to: kroeger98@yahoo.com
Recent revelations about PAXLOVID™ should lead to serious questions for the FDA, CDC and Pfizer
By Kent R. Kroeger (Source: NuQum.com, September 13, 2022)
“In politics, not all lies are all lies. And not all truths are complete.” — Mark McKinnon (American political advisor, reform advocate, media columnist, and television producer)
“The most effective propaganda is surrounded by truths.” — Hanno Hardt (University of Iowa Journalism and Mass Communication Professor)
“Half a truth is often a great lie.” — Benjamin Franklin
Our understanding of social and political issues is incomplete or inaccurate, in part, due to our own mental limitations, but also because those providing us with information on these issues are, themselves, often ill-informed, trying to limit the our knowledge, or simply lying.
No information source has been more responsible for those three information deceits than our own government.
One of the first political science books I read in college was journalist David Wise’s The Politics of Lying — as pertinent today as it was when it was published in 1973. The book outlines how government deception has been enhanced over the years through “official secrecy, a vast public relations machine, and increasing pressures on the press.”
Ironically, it was Wise’s quoting of Richard M. Nixon that has stayed with me all these years:
“When information which properly belongs to the public is systematically withheld by those in power, the people soon become ignorant of their own affairs, distrustful of those who manage them and, eventually, incapable of determining their own destinies.” — Richard M. Nixon
The number of times the U.S. government officials get caught in deliberate deceptions of the U.S. public grows by the day. In my lifetime, it spans from Watergate to Russiagate (with a few –gates in between), but perhaps no deception has been more upsetting than the poor information that has defined too much of the government’s communications effort during the COVID-19 pandemic.
No, I am not an anti-vaxxer or convinced that the virus originated in a Wuhan lab. I am, however, increasingly convinced that the American people were propagandized into believing only expensive vaccine and drug treatments would get us out of this worldwide health crisis — when, in fact, much more cost-effective measures were known or could have been discovered with more high-quality (for example, randomized controlled trials) scientific research.
I am confident in saying that billions of dollars were most likely wasted on the one-size-fits-all vaccine and antiviral policies promoted by the Centers for Disease Control and Prevention (CDC) and pharmaceutical companies. which were ill-conceived and, most certainly, cost-ineffective.
Case in point, the COVID-19 antiviral treatment: PAXLOVID™:
On November 5, 2021, Pfizer announced “its investigational novel COVID-19 oral antiviral candidate, PAXLOVID™, significantly reduced hospitalization and death, based on an interim analysis of the Phase 2/3 EPIC-HR (Evaluation of Protease Inhibition for COVID-19 in High-Risk Patients) randomized, double-blind study of non-hospitalized adult patients with COVID-19, who are at high risk of progressing to severe illness.”
On December 23, 2021, the U.S. Food and Drug Administration (FDA) granted Emergency Use Authorization (EUA) for the use of PAXLOVID™ to treat COVID-19 and the Biden administration has since purchased 20 million treatment courses of the antiviral for use in the U.S.
After initialing reporting that PAXLOVID™ “reduced risk of hospitalization or death by 89 percent (within three days of symptom onset) and 88 percent (within five days of symptom onset) compared to placebo,” in June 2022 Pfizer released the final research findings for the Phase 2/3 EPIC-HR and had to admit their drug offers little benefit to healthy people who are fully vaccinated — which is about one-third of the U.S. population based on data from the CDC and the Yale-Griffin Prevention Research Center.
While PAXLOVID™ is still very effective for people who are unvaccinated or have significant co-morbidities (for example, obesity, hypertension, etc.), Pfizer’s failure to be upfront about a large percentage of the U.S. population who would not benefit from the drug is informative about the forthrightness of not just Pfizer, but the FDA.
The EUA application requirements, as stated in Section E.1 of the FDA’s guidance to industry stakeholders seeking an EUA, are clear in the importance of providing comprehensive evidence as to a drug’s benefits:
A producer of the the drug pursing EUA must provide data on “the significant known and potential benefits and risks of the emergency use of the product, and the extent to which such benefits and risks are unknown.”
In authorizing the emergency use PAXLOVID™, there is no evidence the FDA knew of Pfizer’s clinical study data showing that the antiviral drug was unnecessary for healthy, vaccinated COVID-19 patients.
It would have been a nice thing for family doctors and their patients to know.
An untold millions of Americans (including my wife) received the PAXLOVID™ treatment course for no substantive medical reason. Considering that a five-day course of PAXLOVID™ presumably costs around $530 (the U.S. government paid $5.3 billion for 10 million courses of PAXLOVID™ in November 2021), how many billions of dollars has the U.S. government squandered in facilitating the use of this antiviral treatment for COVID-19?
Before Pfizer’s revelation of the circumstances in which PAXLOVID™ treatments are less effective than originally advertised, in May 2022 the CDC had warned that around 2 percent of people who receive the PAXLOVID™ treatments will have their symptoms return after their initial reduction.
While the CDC says the ‘rebound’ outcome and the drug’s lower effectiveness among healthy, vaccinated people are not serious enough concerns to discourage use of PAXLOVID™, when did Pfizer, the FDA and the CDC know of these effectiveness issues and why didn’t the EUA process bring them to the public’s attention sooner?
This lack of candidness might make someone wonder whether the FDA’s EUA process is more concerned about providing a rationalization for the drug companies’ record-breaking profits than helping the American people make informed medical decisions.
These questions gain relevance after The Economist recently reported that PAXLOVID™ — in the aggregate — has not been particularly significant in saving lives or reducing hospitalizations during the COVID-19 pandemic.
“The impact of Pfizer’s antiviral drug is hard to detect in official statistics,” says The Economist.
It is not just about the money, but that is a good place to start.
All told, the government tab for the COVID-19 pandemic has been staggering:
$10 billion spent on PAXLOVID™ alone.
$20 to $40 billion in total spent on Operation Warp Speed (the joint government-private industry research effort to develop, manufacture and deploy COVID-19 vaccines and antivirals).
Not to mention the $2.2 trillion spent on the CARES Act of 2020 and another $1.7 trillion on the American Rescue Plan Act of 2021.
The U.S. Congress shows no formal interest in asking hard questions of our federal bureaucracy or the drug companies about the critical information kept from the public during the EUA process for PAXLOVID™, not to mention other equally important questions, such as the scientifically specious data used to justify mass COVID-19 vaccinations and boosters of healthy children — money and effort that could have been better spent protecting those most vulnerable to COVID-19.
Adding to the tsunami of secrecy and scientific short-cuts that have helped define the U.S. response to COVID-19, is the FDA’s recent approval of the “bivalent” booster that was issued with no new clinical research to support its deployment into the general public. This virus is too survivable now not to be doing the proper due diligence on the science.
And for all this money and fast-tracking, the U.S. still experienced among the world’s worst fatality rates for COVID-19 (14th worst among over 180 countries with reliable data, according to RealClearPolitics.com). You can thank our fragmented health care system for much of that failing.
Perhaps inadvertently confirming Modern Monetary Theory (MMT) — an economic theory that says countries that issue their own currencies can never “run out of money” the way people or businesses can — our politicians, bureaucrats and corporations appear more than happy to spend government money like drunken sailors, so long as they or their friends get their normal cut.
MMT is probably a closer approximation of our vast economy than its critics want to admit, but nothing in MMT or mainstream economic theory suggests that squandering the government’s money on unproductive endeavors is a good thing.
The opportunity costs alone justify a deeper investigation into how well our money was spent during the pandemic.
Moreover, such an investigation would further expose our dysfunctional health care system and a political culture that is increasingly comfortable with unwarranted secrecy and lack of accountability among its most powerful people — and, hopefully, would prevent our country from making similar mistakes during the next pandemic or health crisis.
- K.R.K.
Send comments to: kroeger98@yahoo.com

Simple liars, damned liars, and experts.
By Kent R. Kroeger (Source: NuQum.com, September 11, 2022)
I’ve written elsewhere about lying. And readers have openly disputed my view on the issue. “Speaking ignorance is a type of lying,” wrote one reader.
No, it is not. Spreading ignorance is what communications researchers call misinformation, which is distinguishable from disinformation, which is the deliberate promulgation of false information (i.e., lying).
Ignorance is not a form of lying. To suggest otherwise is to indict everyone as serial liars.
If your education and experience leads to believing things that are not true, that is not necessarily on you, it can also be the result of the institutions, environment, and peer groups within which you were informed.
Subsequently, when you utter nonsense, you are not a liar — your are just ill-informed. We are all subject to that harsh critique. I utter nonsense on a daily basis. [I believe Aaron Rodgers is the greatest quarterback in NFL history — no joke, I really do.]
I may be wrong on this topic, but I am not a liar. I simply have failed to accept the evidence that contradicts my deeply-ingrained beliefs and impenetrable Packer fandom.
We are all guilty of this type of intellectual failure. Practically speaking, independent of our IQs, experience and education, we can be seduced into wrong, even if well-intentioned, thinking.
Opinions are everywhere.
Men can become women? And vice versa? The U.S. can’t afford a national health care system? The U.S. can afford to pay off student debt for financially insecure students? Nuclear power is safe? The Yemeni Houthis are an existential threat to Saudi Arabia? The 2022 presidential election was stolen? The 2016 presidential election was stolen? Nicolas Cage is one of Hollywood’s greatest actors? These are not necessarily empirical hills on which I would want to die, though I do have opinions on each. But they are just that — opinions, not indisputable facts.
And, and in most cases, a wrong opinion on any issue is not due to getting our information from liars (though they do exist), but more likely the result of the experts we rely who are misinformed and/or biased which subsequently clouds their judgment and, by extension, ours.
It is not a bad habit to question everything you read, hear or see. That doesn’t mean you need to avoid strong beliefs or opinions — but it would be wise to prepare to be wrong.
I always am.
- K.R.K.
Send comments to: kroeger98@yahoo.com
The Rings of Power: The End for Amazon Studios?
By Kent R. Kroeger (Source: NuQum.com, September 8, 2022)
This is not a movie or TV series review. I’m not a Tolkienista by any definition. I reluctantly read The Hobbit in high school (and didn’t love it), ushered my children into all three of The Lord of the Rings movies (because I believed in their potential cultural significance — and they happened to be great movies!), and attended The Hobbit trilogy movies by myself because no one else in my family was interested. I’m a casual fan of J. R. R. Tolkien’s The Lord of the Rings franchise who honestly can’t tell the difference between Rivendell, Minas Tirith, and Osgiliath.
Now for my actual analysis…
Amazon.com, Inc. generated $470 billion in revenue in 2021 and, with over 1.6 million employees, is the 10th largest employer in the world.
Originally, Amazon focused on e-commerce, cloud computing, and artificial intelligence. It is not an exaggeration to say it is one of the most influential companies in the past 20 years.
And, in 2010, Amazon decided that e-commerce, delivering packages and building cloud services was not enough. They also wanted to develop television shows and produce films which would be distributed through theaters and Amazon’s proprietary streaming service, Amazon Prime.
Amazon won its first Oscars in 2017 with Casey Affleck winning for Best Actor and Kenneth Lonergan for Best Original Screenplay in the movie “Manchester.”
Given its sheer financial size, Amazon was an immediate player in Hollywood. So when the company decided to buy the rights to the appendices of The Lord of the Rings: The Return of the King for $250 million in 2017, the buzz immediately shifted to what Amazon would create with their new acquisition.
The answer would be The Lord of the Rings: The Rings of Power (TRP), which premiered on Amazon Prime on Sept 1st.
Amazon has already declared the premiere of their new Lord of the Rings series a success based on their own, tightly controlled, viewing numbers.
The Hollywood Reporters’ Rick Porter however noted: “As for context, there’s little to go on: Prime Video reps declined to say whether that’s an average viewership worldwide on day one, the number of people who watched at least a few minutes of the series, or something else. Nor is there any indication of how much bigger The Rings of Power was than the previous record holder on Prime Video (or what that show was).”
That is the essence of audience statistics in today’s streaming world. It’s mostly self-promoting propaganda.
But we are endowed with independent measures of audience interest, particularly Google’s open-source search data, which gives us a more nuanced story about TRP.
And, bless our luck, we have a real-time comparison case to TRP — it is HBO’s House of the Dragon miniseries, a prequel to the ultra-successful Game of Thrones (2011–2019), which debuted August 21st.
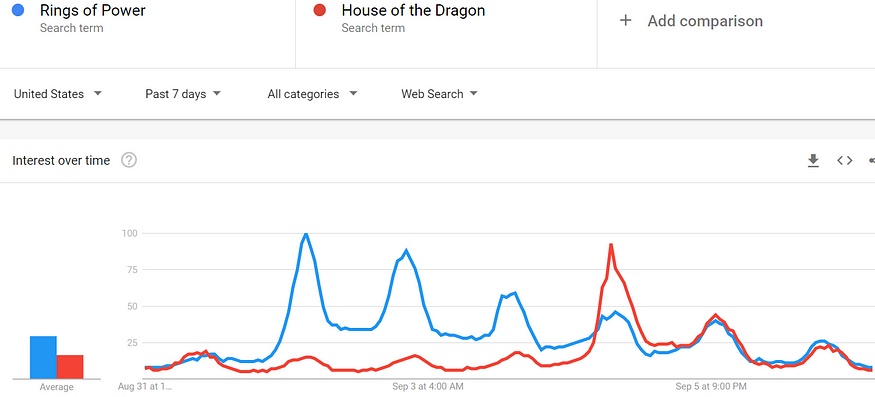
According to Google Trends, which analyzes the popularity of top search queries in Google Search, in the week TRP debuted, it was 76 percent more interesting to Google searchers than The House of the Dragon (see Figure 1).
Figure 1: Google Trends search levels for The Rings of Power versus The House of the Dragon from August 30 to September 6, 2022.
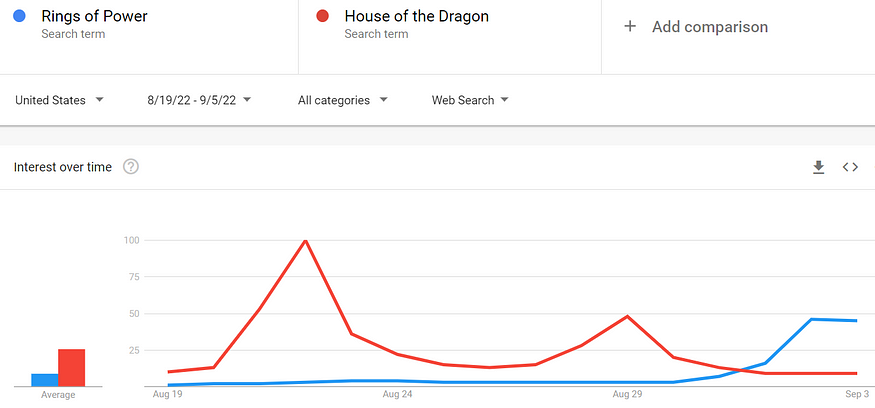
But when comparing Google Trends interest between the premiere week of The House of the Dragon to the premiere week of TRP (see Figure 2), The House of the Dragon was almost three times more interesting to Google searchers than the premiere of TRP.
Figure 2: Google Trends search levels for The Rings of Power versus The House of the Dragon from August19 to September 6, 2022.
Breathless declarations, particularly among J. R. R. Tolkienists (and Elon Musk), that TRP has already failed are premature.
But TRP’s initial audience interest numbers are not what Amazon wanted to see when they decided to spend $500 million dollars on producing the series.
As of now, The House of Dragons is a bigger media phenomenon than TRP. This fact could change if subsequent TRP episodes help grow its audience, but when it comes to the premiere weeks of TRP and The House of Dragons, the latter is the clear winner.
To long time observers of the Game of Thrones and Lord of the Rings franchises, Amazon was facing an uphill task in trying to produce a prequel TV series for The Lord of the Rings more popular than a prequel series for the Game of Thrones.
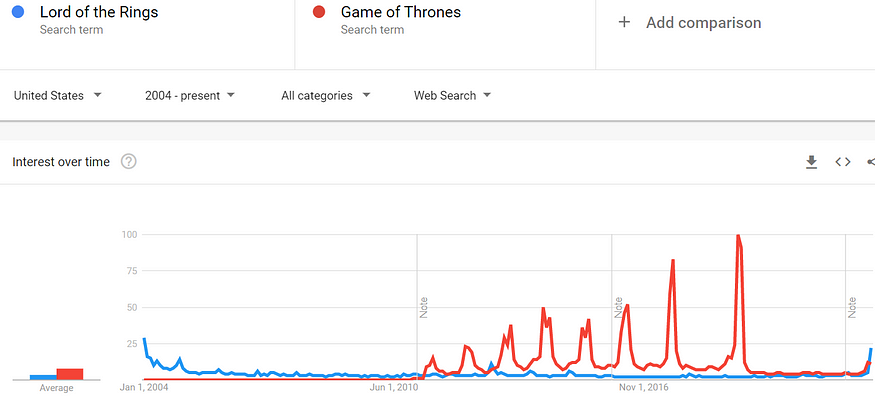
Since the end of Peter Jackson’s The Lord of Rings trilogy in 2004, HBO’s The Game of Thrones franchise is twice as interesting to Google searchers (see Figure 3).
Figure 3: Google Trends search levels for The Rings of Power versus The House of the Dragon from January 1, 2004 to September 7, 2022.
And when compared to Google search interest in the Star Wars and Harry Potter franchises, the Game of Thrones and Lord of the Rings are, together, in a second-class status (see Figure 4).
Figure 4: Google Trends search levels for Star Wars, Harry Potter, The Rings of Power and The House of the Dragon from January 1, 2004 to September 6, 2022.
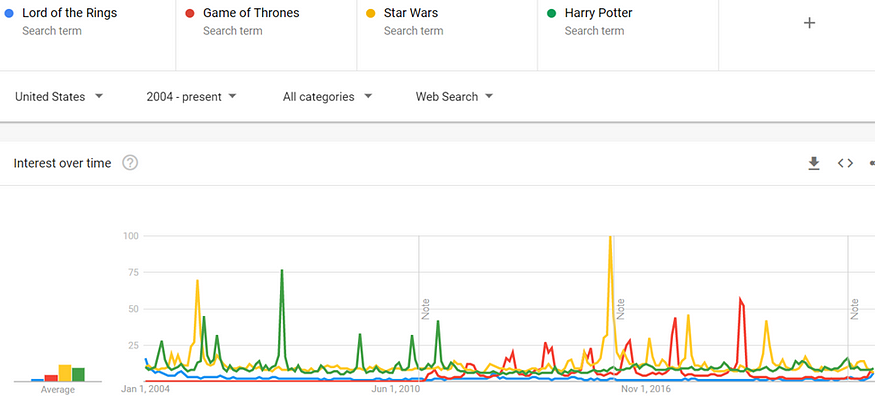
Since 2004, Harry Potter and Star Wars are twice as popular as Game of Thrones and The Lord of the Rings.
If you want to build a marketable media property for the future, the easiest launching pad would be Star Wars or Harry Potter.
The least obvious choice would be J. R. R. Tolkien’s Lord of the Rings franchise.
To Jeff Bezo’s credit, he chose a more difficult path to a media phenomenon.
The next weeks and months will tell us if Bezo’s gamble was worth it.
- K.R.K.
Send comments to: kroeger98@yahoo.com

Disney’s TV version of the Marvel Cinematic Universe underwhelms
By Kent R. Kroeger (Source: NuQum.com, September 1, 2022)
This essay is not a TV or movie review. Personally, I enjoyed the first episode of Disney’s She-Hulk TV series and I’ve been a fan of the She-Hulk character since her Marvel Comics debut in 1980. Instead, this essay is about an objective popularity measure of not just She-Hulk, but all of Disney’s Marvel Cinematic Universe (MCU) TV shows.
I was a comic book fan from the moment I could read (Mad magazine and the original Peanuts paperbacks were most important in that regard). And as I’ve grown older, I’ve met more than a few people (mostly men) with a similar story.
Apart from Mad magazine and Peanuts, my favorite comic book series was Marvel Comics’ The Fantastic Four, featuring Mister Fantastic (He could stretch! It seems like a dumb superpower now, but for a 10-year-old, it was awesome), the Invisible Woman, the Thing, and the Human Torch. From there I would branch into other comic book heroes — X-Men, The Hulk, Daredevil, Superman, Batman, Wonder Woman, Spider-Man and Captain Marvel.
So when the movie version of The Fantastic Four became a reality 17 years ago, I was ecstatic. And though that ensemble was ultimately abandoned (For the love of God, Why?!), the launch of the Iron Man movie series two years later was more than enough to keep me engaged in the first three phases of the MCU movie franchise, culminating in Avengers: Endgame.
Following Endgame, I was satisfied. I didn’t need anymore Marvel superhero movies. But Marvel’s owner, The Walt Disney Company, for obvious monetary reasons, thought otherwise.
Marvel’s creative custodian, Kevin Feige, has ushered in “The Multiverse Saga.” In contrast to the first three Marvel phases, the Multiverse phase includes both movie and TV projects.
I’m not going to address the movie component of the Multiverse — Black Widow, Shang-Chi and the Legend of the Ten Rings, Eternals, Spider-Man: No Way Home, Doctor Strange in the Multiverse of Madness, Thor: Love and Thunder) — as their collective impact on my memory has been minimal. In fact, I have a hard time remembering anything from those six movies except for the joint appearance of the original Spider-Men (Tobey Maguire, Andrew Garfield) with the current Spidey incarnation in Tom Holland.
In many ways, the TV series version of MCU’s Phase 4 has been far more interesting than the movies. WandaVision, as disappointing as its final episode may have been, the show was quirky, funny, and well-acted. That is a recipe for a good TV show.
Which is why the subsequent MCU TV shows have been disappointing and underwhelming.
Again, I’m not doing a TV review, but if we are to understand the data in Figure 1 (below), the quality of the content needs to be considered. According to Rotten Tomatoes (a content ratings service which Hollywood’s powerhouse content providers work hard to manipulate), critics and audiences have loved Disney’s MCU TV shows (the first percentage is based on critics’ ratings and the percentage in parentheses represents audience ratings):
The Falcon and the Winter Soldier — 84% (83%)
Loki — 92% (91%)
Hawkeye — 92% (90%)
What If? — 74% (69%)
Ms. Marvel — 98% (80%)
Moon Knight — 86% (90%)
She-Hulk — 94% (78%)
But do the actual audience measures (Nielsen, etc.) correlate with the Rotten Tomatoes summary of the MCU TV shows?
The short answer is ‘No.’
The TV show with the biggest audience, Paramount’s Yellowstone, has generally positive reviews by both critics and the general public (83% and 84% on Rotten Tomatoes, respectively), but its critical ratings are significantly below Loki, Hawkeye, Ms. Marvel, and She-Hulk.
Yet, which shows actually dominate public interest?
My previous data essays have demonstrated a strong correlation between Google search trends and established audience measures, such as Nielsen’s streaming ratings.
Figure 1 (below) shows the Google Trends search metric for each of the MCU TV shows, plus Paramount’s Yellowstone, which is among the highest rated streaming shows on TV. People actually show an interest in Yellowstone. The same level of interest cannot be said about Disney’s MCU TV shows.
Figure 1: Google Search Trends for Disney’s MCU TV Shows and Paramount’s Yellowstone
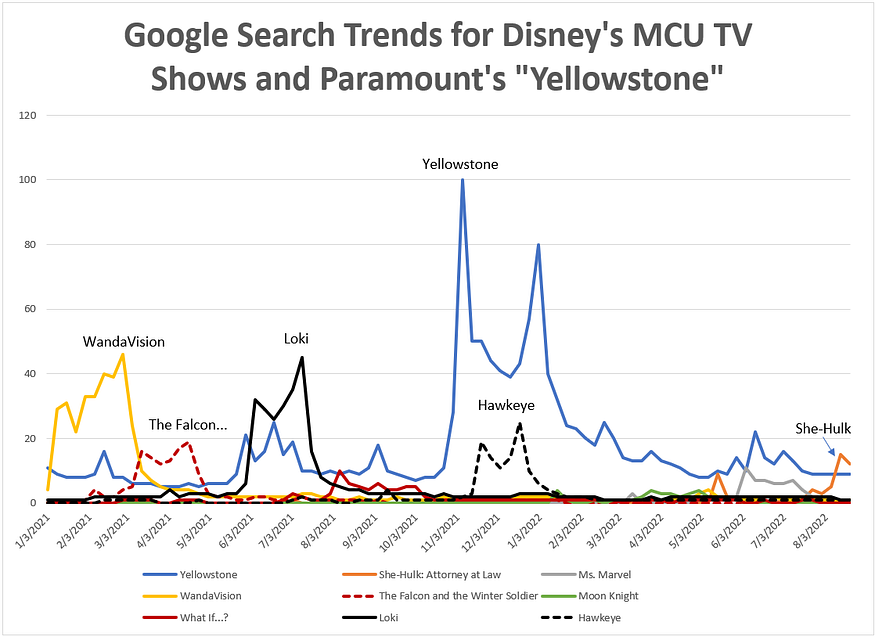
Public interest in Paramount’s Yellowstone crushes Disney’s MCU TV shows. That is not debatable. And having worked with Disney executives in a past professional life, I know The Disney Company lives by the Ricky Bobby principle: If you ain’t first, you’re last.
The declining peaks of the MCU TV shows is unmistakable. Audience interest in WandaVision and Loki was relatively strong (46 and 45, respectively, on the Google Trends Index measured relative to Yellowstone’s search frequency), but the decline in interest for subsequent MCU TV shows — Hawkeye and She-Hulk, in particular — cannot be denied.
Hawkeye’s peak Google Trends Index score was 25 and She-Hulk has, so far, peaked at 15.
This is not a pattern Disney wants for its efforts to make MCU’s Phase 4 a major entertainment event. The data says something to the contrary: Disney is failing to generate interest in its MCU Phase 4 TV shows.
I will let others determine why Disney can’t make MCU’s TV shows an unqualified success. Everyone has theories. But the bottom line is that Disney has squandered the incredible success it generated during the first three phases of the MCU.
Though I am still anxiously anticipating the third Guardians of the Galaxy movie, the more I see what Disney has conjured up since Endgame, my expectations for its entertainment value decreases by the day.
- K.R.K.
Send comments to: kroeger98@yahoo.com

A Still Uncommon Prediction for the 2022 U.S. House Midterm Elections
By Kent R. Kroeger (Source: NuQum.com, August 29, 2022)
[Note: The dataset used in this data essay is available on GITHUB.]
If we aren’t allowed to make mistakes, we will never make progress.
A number readers complained about my U.S. House 2022 midterm prediction — beyond that fact it predicts a GOP landslide win — saying that one of the independent variables in my linear model (average presidential approval from August to October in the election year) required information close to Election Day. As they rightfully point out, in previous essays I have argued that there is little value in a prediction model that requires information right up to the point of the event itself.
The farther out in time your model can predict an event, the more useful your model.
Accordingly, I replaced the presidential approval variable that needed data from late October with one that used the president’s approval at the end of August (Gallup Poll).
Unsurprisingly, the prediction model for the U.S. House 2022 midterms did not change significantly from the previous model (see Figure 1); but, equally without surprise, it does not fit the data as well (adjusted R-squared 0.78 vs. 0.69).
Figure 1: Linear model of House seat gains/losses by President’s Party in Midterm Elections (1950 to 2018)
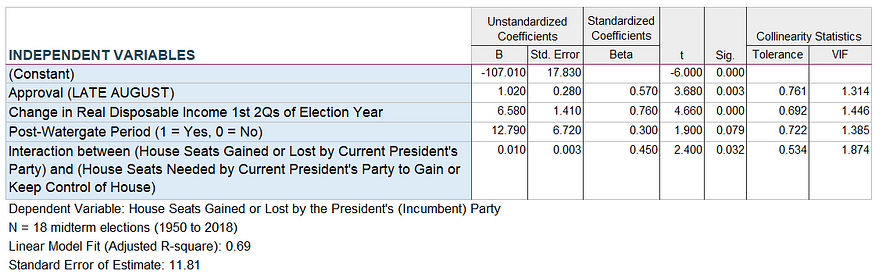
Using August presidential approval data, my model predicts the Republicans will gain 53 seats in November (compared to my previous model’s prediction of a 55-seat gain).
Obviously, this prediction puts me far outside current predictions from mainstream polling and political pundits, some suggesting the Democrats will maintain control of the U.S. House after the 2022 midterms.
They may be right.
But I would remind everyone that Barack Obama had 46 percent presidential approval in August 2010 (and a fast-improving economy coming out of the 2008 world financial crisis) — three months prior to his party losing 63 House seats in the 2010 midterm elections.
I am not surprised that my prediction model — heavily weighted towards economic conditions and presidential approval — should predict a House loss of 53 seats for the Democrats in 2022.
But that doesn’t mean my model is accurate. How has it done in the past?
In 2018, my model predicted the GOP would lose 44 House seats — they lost 40.
In 2014, the model predicted the Democrats would lose 30 seats — they lost 13.
In 2010, it predicted the Democrats would lose 51 seats — they lost 63.
[I would note that the combined predictions for 2010 and 2014 weren’t too far off — I predicted the Democrats would lose 81 seats over those two midterm elections…in reality, they lost 76 seats.]
My model is far from perfect and every recent indicator is telling me it may not work well in 2022.
And why might it fail?
Figure 2, which shows the prediction over time of the largest political futures market in the world (PredictIt), offers a clue.
No, it’s not the U.S. Supreme Courts’ Dobbs decision overturning Roe v. Wade. That decision on June 24th, at best, increased the Democrats’ chance of keeping control of the U.S. House by eight percent. And Speaker of the House Nancy Pelosi’s trip to Taiwan in early August apparently increased the Democrats’ chances by another five percent.
Figure 2: PredictIt Forecast for Control of U.S. House over past 90 days
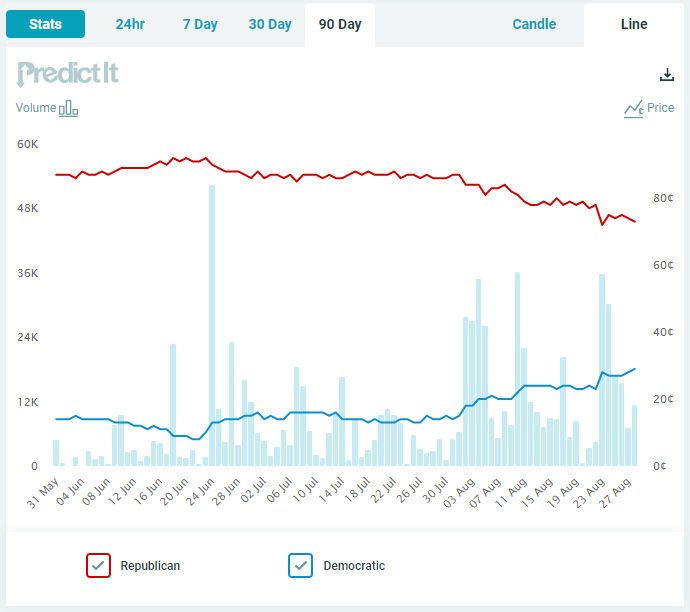
But another event has fundamentally changed the dynamics going into the 2022 midterms: the FBI’s raid on Donald Trump’s Mar-a-Lago home on August 8th.
Since that event, the Democrats’ chances of keeping control of the U.S. House, according to investors on PredictIt.com, has increased from 19 percent to 29 percent.
The Dobbs decision was big, but the Mar-a-Lago raid is bigger and the trend since the FBI raid in the Democrats’ chances of keeping control of the House remains favorable to the Democrats.
How could the Republicans have stumbled so badly in what should be a decisive electoral triumph?
My prediction model says they won’t stumble, but I defer to the podcast-terrifying-monster-to-liberals Ben Shapiro to explain why the GOP might:
Shapiro is right, though I’m not sure why he thinks the Republicans losing momentum is “a mystery wrapped in an enigma.”
It is rather clear in the data why the Republicans are losing momentum.
They’ve hitched their wagon to a man (Trump) who seems disconnected from his own party’s electoral success.
That is not a ticket to success.
I, personally, find the FBI-Mar-a-Lago raid more puzzling than indicative of a major threat to U.S. national security. Am I to believe the U.S. Department of Justice is going to indict of former U.S. president on a vaguely-written, antiquated law (The Espionage Act of 1917) designed expressly to silence dissent against U.S. involvement in World War I and rarely enforced successfully, except in one example where it was used to convict Socialist presidential candidate Eugene V. Debs, the Bernie Sanders of his day, on sedition charges?
Despite being called a “traitor to his country” by President Woodrow Wilson for his opposition to the World War I draft, Debs is today viewed by historians as an articulate, passionate defender of workers’ rights and underclass Americans — hardly a traitor.
Nonetheless, Debs effectively spent his last years of life in an Atlanta federal prison because he had political enemies at the highest echelons of government. Julian Assange knows the routine.
As for Trump, even the establishment leftists at The Atlantic recognize the president’s plenary powers over the classification process, though they assert this power does not extend to nuclear secrets:
“The 1988 Supreme Court case Navy v. Egan confirmed that classification authority flows from the president except in specific instances separated from his powers by law. And here is where things get theological: A president can make most documents classified or declassified simply by willing them so.”
But how can a president be separated from his constitutional powers via a congressional law? A president can’t hand away his or her constitutionally-defined rights any more than an individual citizen can wave off their similarly established rights.
Buzzard’s guts man, as Commander-in-Chief, the president is clothed in enormous power…cue one of my favorite movie scenes of all-time:
My point is not that Trump is legally immune to prosecution for exfiltrating critical national security documents from the White House. It is, however, my contention that partisan proclamations that Trump’s exposure to indictment (and conviction) is self-evident are not only premature, they are not clearly established in existing law and judicial interpretations of that law.
Given the U.S. government refused to prosecute two American Israel Public Affairs Committee (AIPAC) lobbyists on violations of the Espionage Act for passing top secret defense information to the Israeli government and the news media, it seems unlikely they will pursue a similar prosecution against a former president — even if that former president is Donald Trump.
Ultimately, the courts — probably the Supreme Court — will decide if Trump violated any criminal laws.
In the meantime, the American voter, with little interest in the nuances of Constitutional law but peppered day and night on how dangerous Trump is to national security, will decide in November if they’d rather have the Republicans instead of the Democrats in control of the Congress.
The Republicans would be smart to focus on an economy on the brink and a world security situation which, by the day, brings us closer to a hot war — perhaps even a limited nuclear war — with Russia and China.
Are the Republicans dependable enough to handle these critical problems?
If the Republicans want to regain control of Congress, that needs to be the question facing voters in November, not whether Trump violated secrecy laws.
- K.R.K.
Send comments to: kroeger98@yahoo.com

If Sam Harris is right, our democracy paid a steep price in 2020
By Kent R. Kroeger (Source: NuQum.com, August 22, 2022)
With Donald Trump’s most recent FBI investigation drama that includes a set of allegations that, if true, should end his political career, it gets harder every day to muster a coherent defense of the man.
But I don’t have to defend Trump to justify criticisms of his sharpest critics.
Among his most pointed critics in recent has been philosopher and author Sam Harris.
Once one of the right-wing’s favorite “lefties” for his uncompromising criticism of Islam, in a recent interview on YouTube’s Triggernometry podcast, Harris shed his attractiveness to the right’s Trump-wing in a few short sentences:
“I don’t care what’s in Hunter Biden’s laptop. Hunter Biden, at that point (in the 2020 election), could have had the corpses of children in his basement and I would not have cared.
Even if we discovered Joe Biden was getting kickbacks from Hunter Biden’s deals in Ukraine or China, it is infinitesimal compared to the corruption we know (Donald) Trump is involved in.”
Harris then went on to say, out loud, what common people are not supposed to believe about the 2020 presidential election — that a tacit, widely-supported conspiracy existed in the news media and Washington, D.C.’s permanent political class to disallow fair news coverage of Trump’s re-election campaign. The clearest evidence of this conspiracy was as subtle as Trump’s comb over: It was the dishonest and untimely reporting on Hunter Biden’s laptop.
And Harris doubled-down in his defense of this implicit plot among elites to end Trump’s presidency:
“Now that’s doesn’t answer the people who say, ‘It’s still completely unfair to not have looked at the laptop in a timely way and to have shut down the New York Post’s twitter account — that’s a left-wing conspiracy to deny the presidency to Donald Trump.’ Absolutely! It was absolutely right but I think it was warranted.”
In Harris’ opinion, Trump was “an asteroid hurtling towards Earth” who had to be stopped by any means necessary, as dangerous as any fascist dictator from the past — a view still held by many Americans (including most of my family, friends and colleagues).
The New York Times, Washington Post, NPR and other mainstream news outlets would later acknowledge that the laptop-story was not Russian-sourced propaganda or ever discredited by the U.S. Intelligence Community (as reported in those outlets during the 2020 campaign), but coming six months after the actual election, their mea culpa only reinforced the already metastasized belief among the most passionate Trumpers that the 2020 election was “stolen.” The most durable falsehoods are often built on building blocks of truths.
If we broaden our definition of a “stolen election” to include the undeniable and potent media bias arrayed against the Trump candidacy, the term isn’t so conspiratorial sounding. The media’s failure in covering the laptop-story and Harris’ open apologia for the moral righteousness of that failure only hammers home that conclusion.
Contrary to a common retelling of the laptop-story’s timeline, it was not dropped on the American electorate days or weeks before Election Day by right-wing conspiracy theorists. In reality, the “rumor” first appeared on internet news sites in February 2020, according to a GDELT internet news analysis, was reported more substantively in a May 2020 New York Post op-ed article, and began entering the public’s mind in August 2020, according to Google Trends.
The story was there, the media simply refused to cover it. And the irony is, it is doubtful a full news investigation into the laptop-story would have changed the final election outcome, not when so many other media-fueled distortions peppered the American voter before the 2020 election (e.g., Russiagate, Trump-built cages for immigrant kids, Russian bounties on American soldiers, etc.). Trump was sucking swamp water long before Hunter’s lost laptop was found.
The mainstream media’s deliberate mishandling of the laptop-story has only furthered my belief that until we forge a diverse syndicate of news outlets that are unconnected to any political or economic interest, our democracy as idealized in our high school civics classes will never exist.
If we allow the media establishment — print, broadcast and digital — and their political allies to decide a popularly-nominated and legally-elected presidential candidate is unworthy of unbiased news coverage and can be blocked from access to prominent social media platforms, how far removed are we from the autocracies (like Russia and China) our government routinely decries on the international stage?
- K.R.K.
Send comments to: kroeger98@yahoo.com
An Uncommon Prediction for the U.S. House 2022 Midterm Elections
Kent R. Kroeger (Source: NuQum.com, August 21, 2022)
[Note: The dataset used in this data essay is available on GITHUB.]
As energy prices start to fall from their early 2022 highs and President Joe Biden seems to be convincing Americans that the recently passed Inflation Reduction Act (IRA) is truly a landmark piece of legislation, more and more political pundits are calling into question previous predictions that the Republicans are poised to regain control of the U.S. House and Senate in the upcoming midterm elections.
“After months of ‘Democrats are doomed’ chatter, there’s been a definite shift in mood and momentum toward the party in power,” writes Cook Political Report analyst Amy Walter.
In all probability, regaining control of the Senate is a lost cause for the Republicans. When the GOP’s own Senate minority leader, Mitch McConnell, openly questions the quality of the party’s Senate 2022 challengers — Herschel Walker (Georgia) and Dr. Mehmet Oz (Pennsylvania) come to mind — you know things aren’t looking good.
[Note to both political parties: Amateur politicians can often be called by another name: losing candidates. U.S. House and Senate challengers are more successful when they’ve had elective experience at other levels of government.]
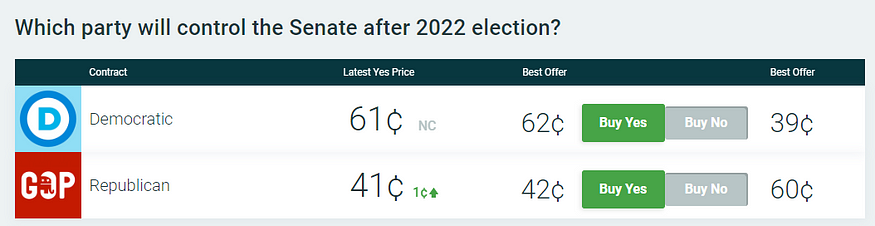
Presently, PredictIt, a political futures market, is giving the Democrats a 61 percent chance of keeping control of the Senate (see Figure 1), and expects the GOP to hold either 48 or 49 Senate seats in the end.
Figure 1: Current PredictIt Forecast for Control of U.S. Senate (as of Aug. 21, 2022)
The news is somewhat better for the GOP’s prospects in the House, where PredictIt still gives the party a 79 percent of regaining control (see Figure 2) — though that is down significantly after the U.S. Supreme Court overturned Roe v Wade in its Dobbs decision in mid-June (see Figure 3).
Figure 2: Current PredictIt Forecast for Control of U.S. House (as of Aug. 21, 2022)
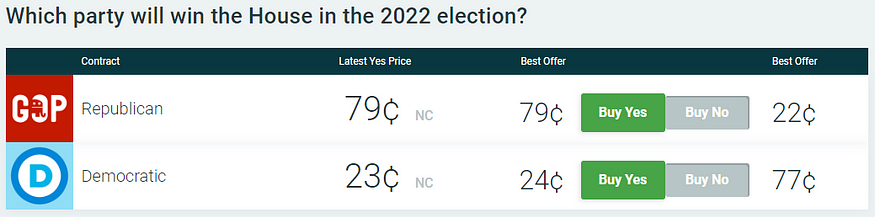
Figure 3: PredictIt Forecast for Control of U.S. House over past 90 days
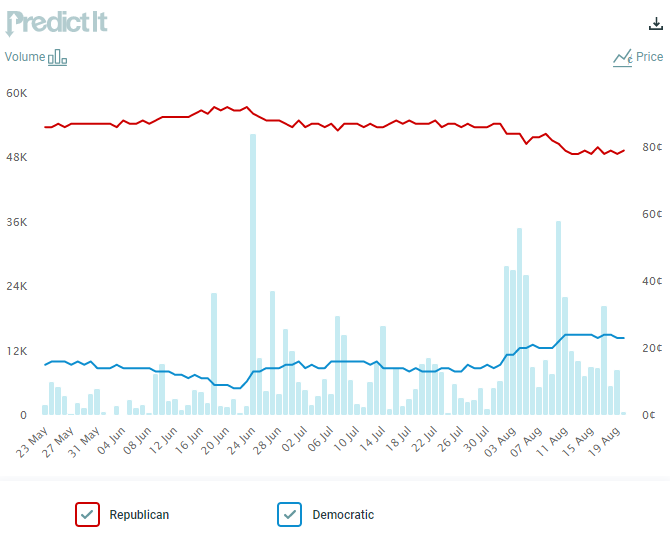
Fivethirtyeight.com gives the GOP a similar probability of regaining control of the House and, likewise, shows that this probability has declined significantly since the Supreme Court’s Dobbs decision.
Are these adjustments in favor of the Democrats warranted?
My Prediction for the 2022 U.S. House Midterm Elections
It is hard to argue that the Republicans haven’t lost significant electoral momentum since the Dobbs decision and the ongoing news that former president Donald Trump is under an FBI investigation for allegedly removing classified defense and security intelligence from the White House as he left office.
If I were a betting man, I would already have dumped my shares in ‘GOP regains Senate’ futures (at a considerable loss, I might add) and would seriously consider hedging my bets on my ‘GOP regains the House’ contracts.
But I am not a gambler. I’m too lazy.
Rather, I like to make my predictions early and stand by them, come hell or highwater.
So here is an econometric model using aggregate data for 18 U.S. House midterm elections (1950 to 2018). The model is based largely on the work of political scientists Michael Lewis-Beck and Charles Tien (2014 midterm model), who were themselves building off the pioneering election forecasting work of economist Ray C. Fair.
With some minor modifications (i.e., binary control variables for the post-Watergate period and the Clinton presidency), the econometric model I estimated to forecast the 2022 U.S. midterm elections is as follows:
Figure 4: Linear model of House seat gains/losses by President’s Party in Midterm Elections (1950 to 2018)
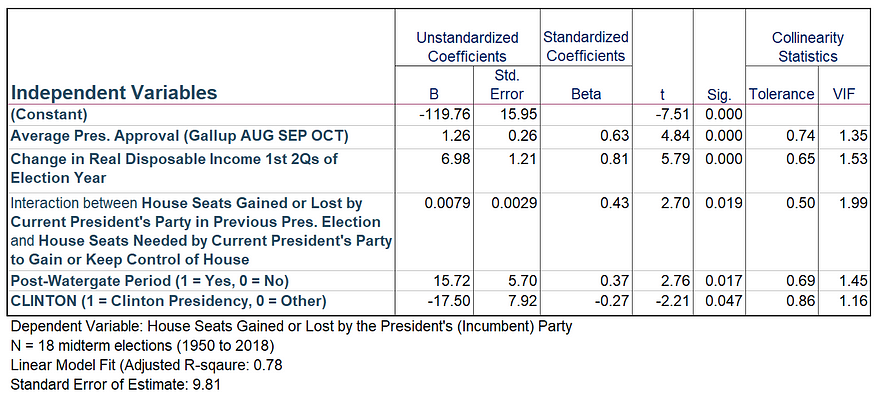
The key independent variables in this model are:
- The average presidential approval as measured by the Gallup Organization for the months of August, September and October in the election year,
- The percent change in real disposable income during the 1st two quarters of the election year, and
- The interaction between two variables: (1) The number of House seats gained (+) or lost (-) by the current president’s party in the previous presidential election, and (2) the number of seats needed by the current president’s party to gain (+) or keep (-) control of the House.
Given the current values (or estimates) for these variables heading into the 2022 midterms:
- Estimate of Average Aug.-Oct Presidential Approval: 41 (RCP’s current aggregated poll measure of Biden’s presidential approval)
- Percent change in real disposable personal income in 1st two quarters of 2022: -0.39 (Source: St. Louis Federal Reserve)
- The number of House seats gained (+) or lost (-) by the current president’s party in the previous presidential election: -13
- The number of seats needed by the current president’s party to gain or keep control of the House: -5,
…my model predicts that the Democrats will lose 55 House seats in the upcoming midterms.
That is definitely a prediction that puts me out of a analytic limb. And why does this model strongly lean towards a Republican landslide, at least in the House races?
This model is driven by the power of economic factors and presidential approval in explaining past midterm elections, along with the tendency that the president’s party usually loses a significant number of seats in midterm elections (an average of 27 in the 18 midterm elections from 1950 to 2018).
Still, a forecasted loss of 55 House seats (!) says a lot about how my forecast model sees the economy and Biden’s approval as too far gone to help the House Democrats in November.
So, as of now, regardless of the genuine anger generated by the Dobbs decision or what happens in the Trump investigation, my forecast model has no reason to believe the economy or Biden’s approval are going to help the House Democrats in the midterms.
- K.R.K.
Send comments to: kroeger98@yahoo.com
On abortion, the GOP chose principles over politics. Will they regret it?
By Kent R. Kroeger (Source: NuQum.com, August 16, 2022)

The Constitution does not prohibit the citizens of each State from regulating or prohibiting abortion. Roe and Casey arrogated that authority. We now overrule those decisions and return that authority to the people and their elected representatives. (U.S. Supreme Court’s June 2022 ruling on Dobbs v. Jackson Women’s Health Organization)
When the U.S. Supreme Court (SCOTUS) ruled on Dobbs v. Jackson Women’s Health Organization that the Constitution of the United States does not confer a right to abortion, the court overruled both Roe v. Wade (1973) and Planned Parenthood v. Casey (1992). As a result, the decision gave individual states the full power to regulate abortion.
The fire and fury from the political left was instantaneous.
“The people who will lose access will be Black women, brown women, poor women, and young women,” said sociologist Kimberly Kelly just prior to the SCOTUS ruling. “If Roe is overturned, abortion is going to become a function of class privilege. Affluent women who can travel, will travel. Only women with certain levels of economic resources will be able to travel.”
“People will die because of this decision,” New York House member Alexandria Ocasio-Cortez said soon after the decision was handed down.
But was the predictable furor warranted?
What the ruling did not do was end legal abortion in the U.S.
To the contrary, the great irony of the Supreme Court’s Hobbs decision is that it will, at a minimum, reaffirm the status quo on abortion as established by Roe v. Wade, and could potentially move the ball further in the direction of unconstrained abortion rights.
States that already strongly affirm abortion rights (e.g., California, New Jersey, Washington, etc.) are poised to further codify those rights. States that used Roe v. Wade to limit abortion rights are likely to legislatively endorse those restrictions.
So how did the Dobbs ruling change the status quo on abortion rights?
It is still early, but most likely the SCOTUS ruling will reduce restrictions on abortion rights for the vast majority of American women.
A recent vote by Kansas voters on abortion rights lays out the problem pro-life advocates face across the U.S.:
An increase in turnout among Democrats and independents and a notable shift in Republican-leaning counties contributed to the overwhelming support of abortion rights last week in traditionally conservative Kansas, according to a detailed Associated Press analysis of the voting results.
A proposed state constitutional amendment would have allowed the Republican-controlled Legislature to tighten restrictions or ban abortions outright. But Kansas voters rejected the measure by nearly 20 percentage points, almost a mirror of Republican Donald Trump’s statewide margin over Democrat Joe Biden in the 2020 presidential election.
Does the Kansas vote on abortion rights expose the GOP’s vulnerability on abortion?
Of course it does.
The GOP refuses to accept that the U.S. social consensus on abortion is that it should be legal, with restrictions only on late-term abortions.
The GOP can argue the morality of abortion to the end of times, but their policy prescriptions are only impactful if they can get the majority of Americans to legislatively agree with their abortion policies.
Kansas is evidence that they face an uphill battle.
Through the Hobbs decision, SCOTUS gave the abortion decision to states, and, in practicality, is bringing U.S. abortion law into alignment with public opinion.
As someone who calls himself pro-life, I am wholly aware that my views on the issue are at odds with most Americans. I am pro-life in a country that has few qualms about exterminating the unwanted unborn.
“They are just a collection of cells.” “They aren’t sentient.” “They don’t feel pain.” “Human life begins after the baby exits the womb.”
I’ve heard all of those rationalizations and intellectual gymnastics in justifying a pro-choice position. I disagree with those arguments, but I also recognize that this is the public consensus on abortion in the today’s United States.
And the GOP may be reminded of that reality in the upcoming midterm elections.
U.S. state-level public opinion on abortion
The American National Election Studies (ANES) project, funded by the National Science Foundation and currently managed by the University of Michigan and Stanford University, conducted a national survey of 8,280 vote-eligible U.S. adults before the 2020 presidential election.
Among the questions asked in that survey was a question on how respondents placed themselves on a 5-level scale regarding abortion rights:

According to the 2020 ANES, 61 percent of U.S. adults believe, at a minimum, abortion should be allowed “after the need…has been clearly established.”
The results of this survey, unaffected by the SCOTUS’ Hobbs decision, indicates the national consensus on abortion is that it should be legal and only restricted when the need to abort the child is not clearly established.
I am pro-life, but I live in a pro-choice country. I can pretend otherwise, but that would make me delusional.
Among those states with enough ANES sample cases to be analyzable, public opinion in 74 percent of states support abortion rights when a need is established (see Figures 1a —1g).
Figure 1a: Abortion attitudes in the Northeast U.S.
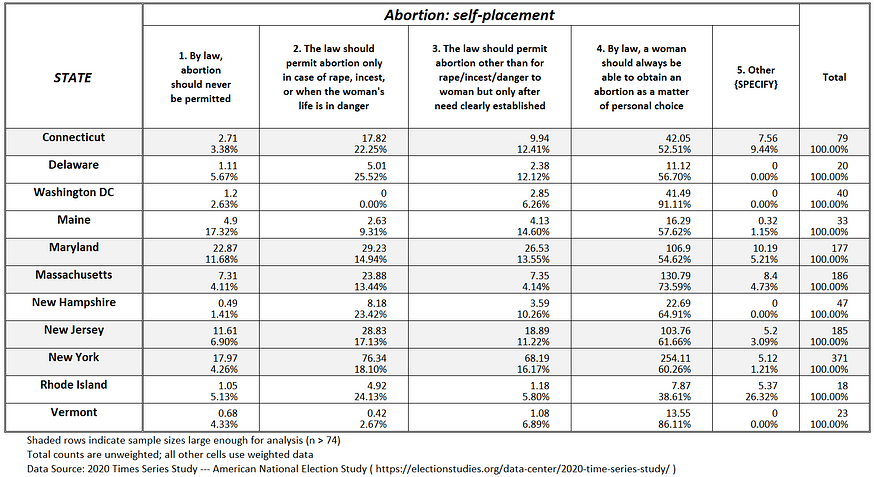
Figure 1b: Abortion attitudes in the Southern U.S.
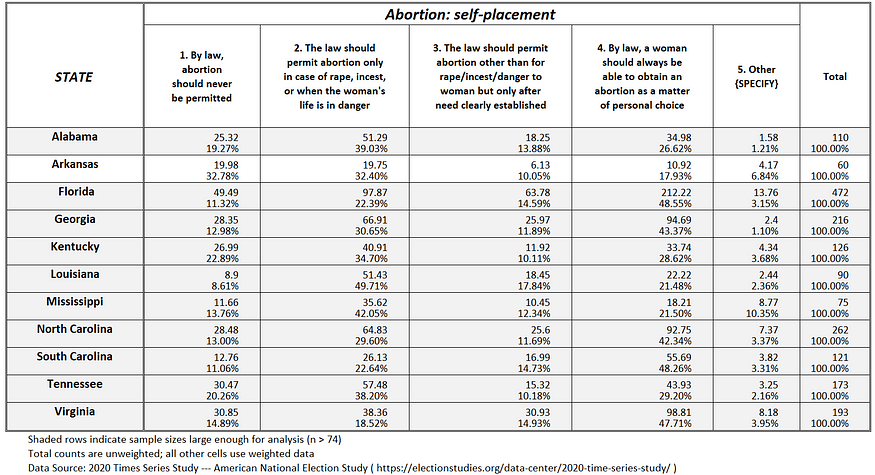
Figure 1c: Abortion attitudes in the Industrial Mideast U.S.
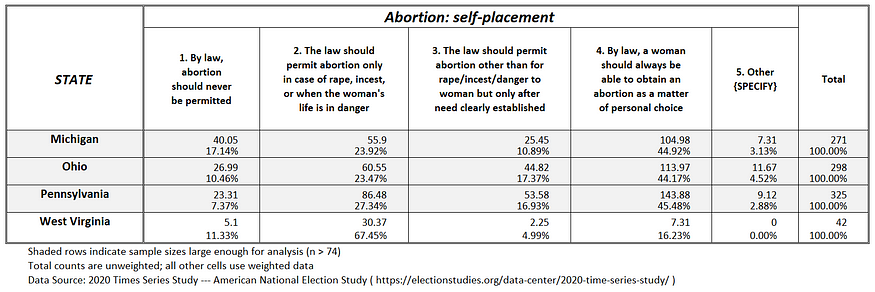
Figure 1d: Abortion attitudes in the Upper Midwest U.S.
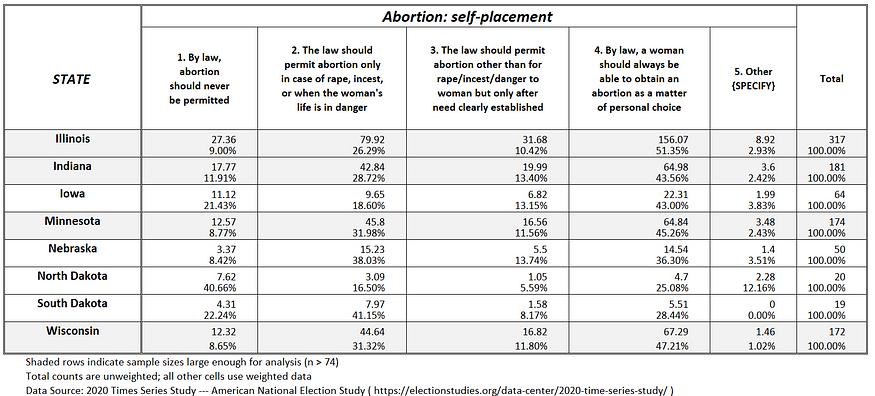
Figure 1e: Abortion attitudes in the Lower Midwest U.S.
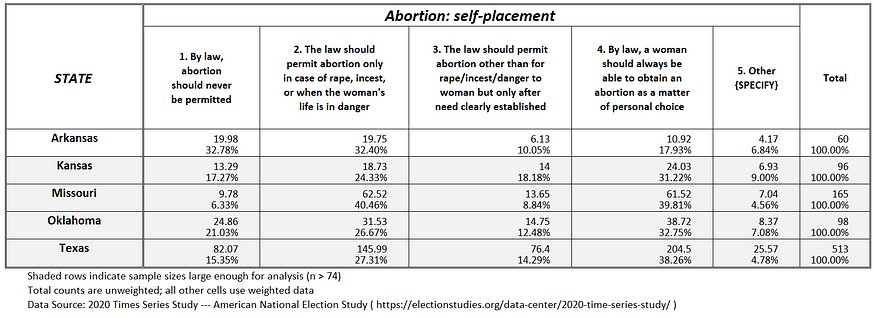
Figure 1f: Abortion attitudes in the Mountain U.S.
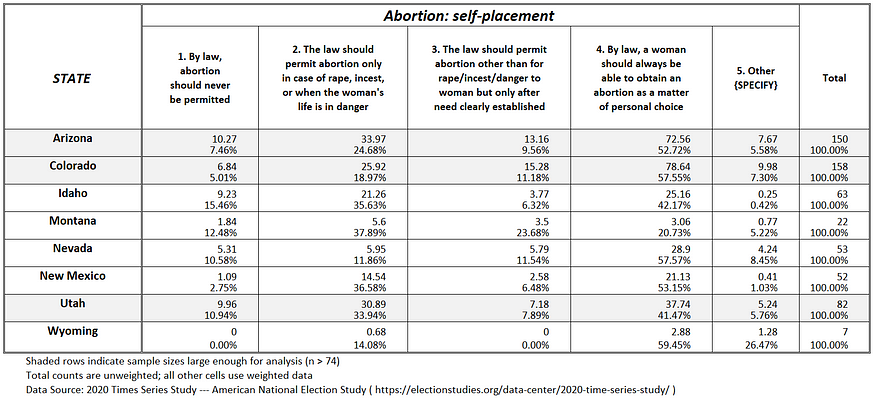
Figure 1g: Abortion attitudes in the Pacific West U.S.
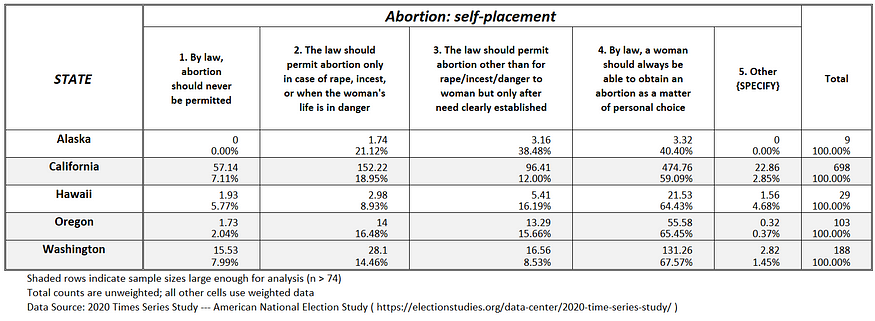
In the U.S. today, public opinion leans decisively against the pro-life position.
I am resigned to that reality.
But what I cannot understand is the unwarranted hyperbole of people like Dr. Kelly and Rep. Ocasio-Cortez who suggest the Hobbs decision will rollback abortion rights in the U.S.
The exact is opposite is going to occur — and Kansas is the first example of this dynamic.
If one compares existing abortion policy in the 50 states (plus D.C.), as shown in the title graphic, with actual public opinion (see Figures 1a-g), it suggests that when the abortion issue is presented to voters, at least 20 out of the 50 states (plus D.C.) will reduce restrictions against abortion, not increase them (States likely to reduce abortion restrictions include: Alabama, Arkansas, Florida, Georgia, Indiana, Iowa, Kentucky, Louisiana, Massachusetts, Missouri, Nevada, Ohio, Oklahoma, Pennsylvania, South Carolina, South Dakota, Texas, Utah, Virginia and Wisconsin).
For example, post-Hobbs, Alabama has effectively banned abortion, according to the Guttmacher Institute. Yet, based on public opinion in Alabama as measured by the 2020 ANES (see Figure 1b), 80 percent of adult Alabamans believe abortion should be allowed at least in cases of rape, incest, or when the woman’s life is in danger.
And it is not just in the American South where state abortion policies are disconnected from public opinion. Wisconsin is a state with significant restrictions on when an abortion can occur (again, see a Guttmacher Institute analysis of state-level abortion policies); yet, public opinion in the state (see Figure 1d) indicates 59 percent of Wisconsin residents believe abortion should be allowed after a need is established, irrespective of how long the woman has been pregnant.
The strongest conclusion one can draw is that state’s like Alabama and Wisconsin are going to reduce abortion restrictions, not increase them post-Hobbs.
Only three states — Idaho, Montana, and (maybe) Rhode Island — will potentially rollback abortion rights once the issue is brought before voters. But they are the exception.
It is true that having a directly expressed constitutional right (e.g., freedom of speech, religion, privacy, and gun ownership) is a more irrevocable right than a right dependent on voter approval or implied-right arguments. But it is also true that public opinion drives election outcomes far more directly than sometimes abstract constitutional rights.
Current polling data says abortion is now one of the most important issues among voters heading into the 2022 midterm elections.
I suspect the Republicans have squandered their many advantages heading into the 2022 midterm elections. Sure, they may well regain control of the House of Representatives, but are they in any position to lead the country?
If I were a Democrat, I would be quietly cheering the Hobbs decision — it can only help the Democrats’ prospects in the midterm elections. If I were a Republican, I would spend the next four months focusing on inflation, economic stagnation, and the aching incompetence of the current administration.
- K.R.K.
Send comments to: kroeger98@yahoo.com

Inflation Reduction Act is the motherload of bad policy ideas
By Kent R. Kroeger (Source: NuQum.com, August 9, 2022)
From elementary to high school, I was a short and skinny kid who was frequently subjected to various forms of socially acceptable peer group torture, the most common of which was the noogie headlock.
A guy wraps his arms around your neck from behind, bends you over and starts grinding his index finger’s proximal interphalangeal joint (i.e., knuckle) into the boundary between your frontal and parietal skull bones.
It hurt, but it was a tolerable level of pain compared to some other bullying alternatives.
For example, a snuggies attack, the process in which someone reaches into your pants from behind and grabs your Fruit of the Looms (i.e., underwear) and attempts to pull them over your head.
While that attack hurt less than the noogie, it inflicted far more emotional pain, particularly when conducted in front of fellow students.
Luckily, God blessed me with a low center of gravity and exceptional twitch muscle speed that helped me avoid most snuggie attacks.
Noogies, however, were another matter. Once they had your neck in a grip, they owned you. And to fight back it required a different set of fighting skills to weather the demoralizing fury of an unforeseen noogie attack.
And while my younger self was never a master of hand-to-hand combat techniques, occasionally I could resist a noogie strike by using my free, outside arm to land a few solid, but usually ineffective punches at my attacker’s crotch.
Inevitably, the response to such a countermove was for my attacker to grind his knuckle into my skull even harder — to the point where it actually hurt — forcing me to withdraw my crotch-directed response and, instead, utter the internationally-accepted indication of unconditional defeat, “Uncle!”
I bring up these traumatic childhood memories because I believe they are a metaphor for policymaking in the U.S. today.
Most Americans live in a perpetual noogie-hold courtesy of corporate America, whether they know it or not. And no piece of national legislation better exemplifies that condition than the Inflation Reduction Act of 2022, recently passed by the U.S. Senate and certain to end up on President Joe Biden’s desk for signature sometime in the near future.
What is wrong with the Inflation Reduction Act of 2022?
The Inflation Reduction Act (IRA) is anything but a public policy designed to reduce inflation. Instead, it is the motherload of bad policy ideas, designed more to help the wealthiest Americans than to impact, in a positive way, the lives of regular Americans.
How do I know? Read the text.
If taming inflationary pressures is the primary bill’s goal, Part 1 of the bill (Corporate Tax Reform 5 Sec. 10101. Corporate Alternative Minimum Tax) is an inauspicious start.
Ostensibly, the bill’s intent to raise government revenues by initiating a 15-percent minimum tax on large corporations could easily be a Bernie Sanders idea. But, in reality, it is not.
Firstly, accelerated depreciation is exempted. That is, compared to straight-line depreciation, this provision allows more depreciation of an asset’s life in its earliest years (and less in later years). In practice, according to corporate tax experts, accelerated depreciation encourages wasteful tax shelters, drains revenue from the U.S. Treasury, is irrelevant to small businesses, and does little to help the economy.
But, more importantly, this provision potentially increases inflationary pressures, not decrease them.
Why? Because if you are a company facing a drain on your bottom line there are two primary options: lowering costs (such as laying off workers) or raising revenues through price increases on the goods and services you offer customers.
Neither is good for the economy.
In other words, corporate America has consumers in a perpetual noogie-hold and raising their costs of doing business through higher taxes (i.e, landing a figurative crotch shot) only backfires in the long run through higher unemployment or higher prices.
OK, so we are off to a bad start with the IRA. How about its other provisions?
Thanks to Arizona Senator Kyrsten Sinema, a Democrat, the IRA no longer includes a provision to close the carried interest tax loophole that benefits private equity and hedge fund managers (a loophole even uber-capitalist Donald Trump opposed). Instead, Sinema allowed a one-percent excise tax on stock buybacks that, in theory, brings in more revenue than eliminating the carried interest tax loophole as it will likely incentivize companies to issue dividends instead, which are taxed when issued.
As to its effect on stock prices or the macroeconomy, Wall Street expects little impact.
Very well, the tax provisions in the IRA are, at best, unlikely positively impact inflationary pressures, and could potentially have the opposite effect.
But fear not, the IRA applies the brakes on the primary cause of inflation — economic growth — by unleashing the Internal Revenue Service (IRS) on tax-paying Americans who are the least equipped to defend themselves from a federal tax audit.
According to the current IRA bill (which still has to go through the U.S House), the number of IRS agents and audits will double. And the target of these additional audits most likely will not be the wealthiest Americans, but instead, average U.S. households.
And if the Democrats achieve their stated aims with the IRA, the increased IRS audits will generate at least $124 billion in increased tax collections over the next 10 years.
In comparison to a $23 trillion dollar annual economy, that may not seem like a growth-crushing number, but it will be to the millions of Americans who find themselves in the crosshairs of an IRA bureaucracy that will become bigger and (dare I say) more powerful than the Pentagon.
Well, at least the IRA has one provision that will most certainly suppress economic growth and, in turn, curb inflationary pressures.
What other damage could the IRA do to this country?
If you are a fan of wealth inequality, the IRA is also likely to direct even more money to the wealthiest Americans through the more than $300 billion earmarked to fund “investments” in attacking climate change and boosting the growth of clean energy. The most visible financial handouts will be to those Americans able to purchase electronic vehicles (EVs) such as bargain-end Tesla’s currently selling for around $50,000, but farmers and ranchers will also get their share of the jackpot through cash incentives for reducing methane emissions (e.g., cow farts).
But that is not the most toxic element of the IRA that will increase wealth equity; instead, the bill will fund the launch of the National Climate Bank which will be tasked to make “investments” in clean energy technologies and energy efficiency — or, as I would put it, an additional bureaucracy authorized to print money that will be immediately transferred to corporate accounts through loans and the federal contract process.
Who will benefit most by this spending? Corporate executives.
Hey, it’s a free market. I don’t fault companies for exploiting the federal government’s ability to print money. However, I do fault the politicians — Democrats and Republicans — that confuse federal spending with actually solving a national problem (e.g., climate change). And, trust me, nobody will be held accountable if in 10 years the U.S. is emitting more greenhouse gases than ever and little has been done to actually address our warming planet.
My prediction is that the IRA’s $300 billion will be pissed away faster than you can say Solyndra.
Even though his companies have received billions in government subsidies — and why would anyone expect him to turn them down? — Tesla CEO Elon Musk has repeatedly said the U.S. government is not a good “steward of capital.”
Is there anything good in the IRA?
Despite the private-equity lobby winning again, the IRA does have provisions that are net positives according some progressive economists.
The most cited provision that will primarily help Americans 65 and older is the one that empowers Medicare to negotiate prices with drug companies. This a policy that has been pursued by progressives for years and now, finally, has a real chance of becoming a reality. Additionally, this potential savings in prescription medicines will help fund a three-year extension of government subsidies supporting the Affordable Care Act (ACA) that would have expired next year.
That is a big deal and should not be diminished.
The Bottom Line on the IRA
Progressives are having a hard time getting excited about the IRA.
Vermont Senator Bernie Sanders tries, but the constipated look on his face when he attempts to defend the bill says more than his measured words:
https://cdn.embedly.com/widgets/media.html?src=https%3A%2F%2Fwww.youtube.com%2Fembed%2FcudBaqbXsQE%3Ffeature%3Doembed&display_name=YouTube&url=https%3A%2F%2Fwww.youtube.com%2Fwatch%3Fv%3DcudBaqbXsQE&image=https%3A%2F%2Fi.ytimg.com%2Fvi%2FcudBaqbXsQE%2Fhqdefault.jpg&key=a19fcc184b9711e1b4764040d3dc5c07&type=text%2Fhtml&schema=youtube
In short, Sanders is saying everything he proposed to make the bill acceptable was rejected by his own party.
If anyone remains deluded that the leaders of the Democratic Party are good for progressive policy ideas, now is the time to end such conceits.
The IRA is a crappy bill, anti-progressive to its core, that will do little to reduce inflation, stop climate change, or lower the national debt; but, instead, could undue the electoral advantage the Democrats gained with the Supreme Court’s overturning Roe v. Wade. Its a bad bill openly designed to help the privileged few whose lobbyists crafted it.
The Democrats, not just progressives, may well regret passing it.
- K.R.K
Send comments to: kroeger98@yahoo.com

Both the Democrats and GOP have some good ideas, but never call me a ‘Centrist’ or ‘Moderate’
By Kent R. Kroeger (Source: NuQum.com; August 5, 2022)
I get this question all the time: If you don’t love the Democrats or the Republicans, do you consider yourself a centrist, undecided, independent or moderate?
Not only is the answer, no, but I couldn’t be further from the ‘centrist,’ ‘undecided,’ ‘independent’ or ‘moderate’ labels.
I respect bold ideas and policies: Medicare for All. The end of our forever wars. Cancelling student debt. Aggressive policies to end our reliance on fossil fuels. A pro-nuclear energy policy. Ending the carried interest loophole. Less government. Lower taxes. A simple, flat national consumption tax.
Those are hardly centrist, undecided, independent or moderate positions. I’m all over the ideological map.
And the survey data reinforces this understanding of centrists, undecideds, independents and moderates: Like me, they are ideologically diverse. Writes analyst Lee Drutman for fiverthirtyeight.com:
“Anybody who claims to have the winning formula for winning moderate, independent or undecided voters is making things up. Perhaps more centrist policies will appeal to some voters in each of these categories — but so will more extreme policies.
Moderate, independent and undecided voters are not the same, and none of these groups are reliably centrist. They are ideologically diverse, so there is no simple policy solution that will appeal to all of them.”
Do tell.
Drutman’s conclusions make me wonder why we are stuck with only two major political parties when, by his estimate, 44 percent of vote eligible Americans in 2020 fell into this ‘murky’ middle.
Do we not deserve at least one third party option? No, says our political elites.
The primary reason for our lack of multiple political parties is that our electoral system (i.e., ‘first-past-the-post’) forces us towards just two viable parties — and our media and political elites reinforce that pressure.
But, of course, nothing in our constitution says this has to be the way it is. Political and economic elites dictated to us that this is what we have to accept.
As I was forcefully told by Teresa Vilmain, a high-ranking campaign operative on Tom Harkin’s 1984 Iowa Senatorial campaign, during my paid stint as a door-to-door fundraiser on that campaign, “We are a two-party system. Don’t let people tell you they aren’t committed to the Democrats or Republicans. They are no other choices.”
That sums up our political system, but Vilmain’s dictum never represented my attachment to the two major parties. Iowans deserved choices other than Tom Harkin or Roger Jepsen (the GOP incumbent) in 1984’s Iowa Senate race.
Fast forward to the present, nothing has changed for the better in our political system since 1984— in fact, things have gotten worse — so forgive me if I could care less if the Republicans or Democrats control the Congress after the 2022 midterm elections. The average American is screwed no matter which party wins.
If only an ideologically transcendent political leader could arise in my lifetime. But, don’t worry, I’m not holding my breath.
- K.R.K.
Send comments to: kroeger98@yahoo.com
International law is a fiction
By Kent R. Kroeger (Source: NuQum.com; August 3, 2022)
International law consists of rules and principles governing the relations and dealings of nations with each other, as well as the relations between states and individuals, and relations between international organizations. (Cornell Law School)
The overarching goal of this blog is to highlight analytic tools and data that are available to everyone. Today, however, I am going off-script to address an issue that is close to my heart and represents an early part of my career.
I taught a survey class in International Politics and Law at the University of Iowa almost 30 years ago, and though I was an only marginally effective instructor, my students were exceptionally engaged on the question of international law.
Does international law actually exist?
One student in particular, who served in the Army reserve and who had been deployed on a United Nations (UN) peacekeeping mission, aggressively disagreed with the contention that the UN, or any other international organization, represents a ‘legal authority’ that can sanction or punish a rogue nation independent of the will of a major world power (i.e., the U.S.).
The student offered this observation: “If I steal a car, I broke the law and will be arrested by the police. What police force stops me from stealing a country?”
“The U.S.,” answered a student.
But the U.S. is not an international organization. It is a nation-state, a powerful one at that.
Current events have brought this issue to the forefront: Vladimir Putin claims Ukraine is historically part of a greater Russia (not true), and the Communist Party of China argues that Taiwan is a breakaway province (true) that is inseparablypart of the People’s Republic of China (not true).
What international laws validate Russia and China’s claims of sovereignty over Ukraine and Taiwan?
The answer is that there is no such international authority. Historical claims of sovereignty, like Russia’s and China’s, are feckless and impotent separate from their military and diplomatic ability to acquire those territories.
Only nation-state power determines national boundaries. There is no international body that governs these definitions. Only hard and soft power can decide what constitutes an independent nation-state.
The informal rules that govern the definition of a sovereign nation-state have not changed since the Peace of Westphalia in 1648, which recognized the inviolability of nation-state borders and endorsed non-interference from external sovereign states in the domestic affairs of individual sovereign states.
This latter aspect of Westphalia has been violated many times over. Today, powerful countries interfere directly in the internal affairs of weaker countries on a daily basis — and there is no international legal authority that can stop this.
As to the former impact of Westphalia, it remains true todaythat independent nation-states exist because their governing authority controls ‘lethal’ power within a definable national boundary, and most countries (particularly powerful ones) recognize that control.
That is what makes a ‘legal’ nation-state. Nothing more, nothing less.
Israel has understood this reality from its inception. And, today, the only barrier to Israel annexing the West Bank is their acknowledgement that the international community will not accept such a move.
Set aside your media-fueled belief that international law stands against Russia’s control of the Donbass region of Ukraine or China’s claim to Taiwan: The reality is that nation-state powers like the U.S. will decide those outcomes.
International law is a fiction.
- K.R.K.
Send comments to kroeger98@yahoo.com
Addendum: What about the Nuremburg trials?
Since posting this essay I’ve had a number people push back with valid questions: What about the Nuremburg trials after WWII? And what about the International Court of Justice (ICJ) or the International Criminal Court (ICC)?
Are these not concrete examples of international law in action?
No, they are not. They are fundamentally dependent upon the cooperation of nation-states for their legitimacy.
Let us start with the Nuremburg trials. The charter that created this tribunal limited the jurisdiction of the court to Germany’s actions in World War II, largely because the Allied nations (U.S., U.K., France and Russia) did not want to face legal challenges to their actions during the war.
The Nuremburg tribunal was a creation of the nation-states that won the war. It was in no way a legal tribunal independent of the nation-states that created it. It was law determined by the victors in WWII.
The ICJ is a more interesting example. Is it an international judicial authority that can make judgments against nation-states, or individuals within those nation-states, independent of the recognized sovereignty of those nation-states?
The answer, again, is an emphatic No!
The ICJ is the principal judicial organ of the UN. It was established in June 1945 by the Charter of the UN. It is, at its inception, a product of nation-states entering into a multilateral agreement. Its authority is solely dependent upon the nation-states that agree to its powers.
The ICC is similarly a product of nation-states. On 17 July 1998, the Rome Statute of the ICC was adopted by a vote of 120 to seven, with 21 countries abstaining. The seven countries that voted against the treaty were China, Iraq, Israel, Libya, Qatar, the United States, and Yemen.
The ICC’s authority is completely dependent on the nation-states that support it. Subsequently, the U.S. routinely denies the authority of the ICC.
In contrast, if the U.S. government wants to prosecute a U.S. billionaire for wrongdoing, the billionaire cannot unilaterally declare they are not subject to U.S. law. They must, instead, defend themselves in a U.S. court of law.
That is why international law remains a fiction compared to the actual legal authority of a nation-state.